News articles

New project launches to improve understanding of cholangiocarcinoma care across the UK
A new national audit project is launching its first phase, aiming to improve understanding of how cholangiocarcinoma (CCA) is managed across the NHS. The Cholangiocarcinoma (CCA) Audit Project, managed by Health Data Insight (HDI) and funded by AMMF – The…

Third Endometrial Cancer Audit Pilot (ECAP) Report published
A new report from the Endometrial Cancer Audit Pilot (ECAP) offers insight into how women in England are diagnosed with endometrial cancer, alongside trends in the recording of tumour genomic testing and the use of immunotherapy. Published in May 2026, the third ECAP…
New Project Launch: Post Imaging Pancreatic Cancer Root Cause Analysis (PIPC)
Health Data Insight CIC (HDI) are pleased to announce the launch of the Post Imaging Pancreatic Cancer (PIPC) Root Cause Analysis (RCA) Project, a national project to improve the early diagnosis of pancreatic cancer. Pancreatic cancer is often diagnosed at a late…

New research highlights how cancer stage at diagnosis impacts NHS hospital care costs
A major new study led by Health Data Insight CIC (HDI) Senior Health Data Analyst Clare Pearson has been published in Lancet Oncology, providing a detailed picture of how NHS hospital care costs vary by stage at cancer diagnosis in England. The research, carried out…

Endometrial Cancer Audit Pilot (ECAP) Treatment Report published
Following on from the publication of a baseline report last year, the Endometrial Cancer Audit Pilot (ECAP) has published its second national report , focusing on the treatments received by women diagnosed with endometrial cancer in England between 2017 and 2019. …
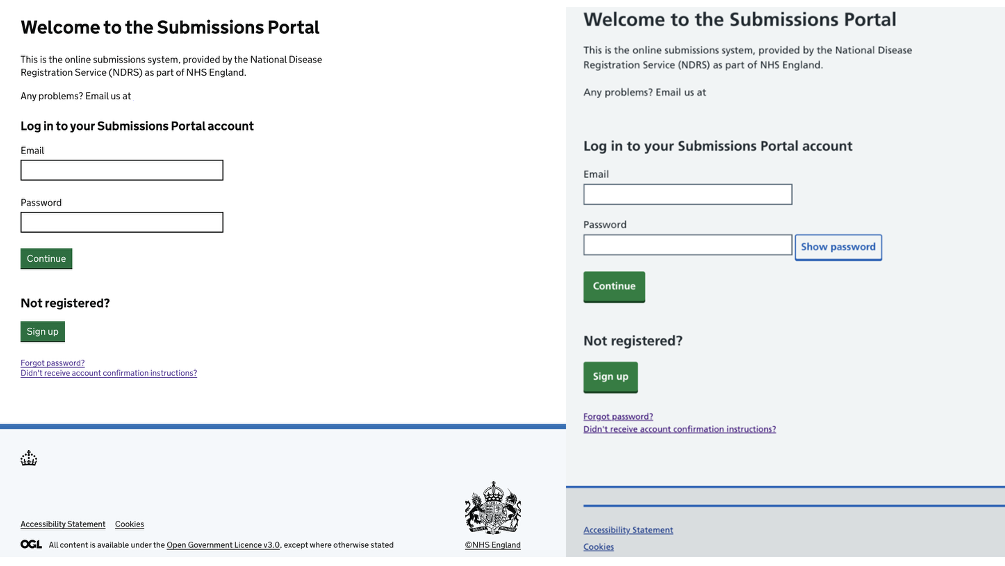
Launching the new Design System Gem
At HDI, we believe that good design is fundamental to delivering trusted, accessible digital services. Our work across the NHS and wider public sector often involves building systems that must meet rigorous usability and accessibility standards while maintaining a…

HDI Summer Internship 2026 Applications Now Open
We’re excited to announce that applications for the HDI Summer Internship Programme are now open. Our HDI Internship Programme gives you the opportunity to work on real-world projects that use data to improve healthcare outcomes. Past interns have developed tools to…

Results from the PCCRC audit have been published
Recent findings published in the journal Endoscopy have found that 69% of post-colonoscopy colorectal cancers (PCCRCs) could have been prevented. The paper, entitled “National root-cause analysis of 1724 post-colonoscopy colorectal cancers demonstrates avoidable…

Synthetic Data Demonstrates Major Benefits for Cancer Research
A new paper authored by NHS England, IQVIA, Amgen and Health Data Insight (HDI) highlights how HDI’s synthetic dataset, Simulacrum, is transforming cancer research in England. The paper ” Leveraging synthetic data to facilitate research: A collaborative model for…